 Why InfiSight
Why InfiSight AI at InfiSight
AI at InfiSight 门店智能督查
门店智能督查 AI 员工培训
AI 员工培训
 24h AI 门店管家
24h AI 门店管家 空间客流应用
空间客流应用 公司介绍
公司介绍 智睿博客
智睿博客
 AI at InfiSight
AI at InfiSight AI 员工培训
AI 员工培训超越还是颠覆?DeepSeek 与 OpenAI 的差异解析
在好莱坞动画工厂的流水线与硅谷 AI 实验室的算力霸权之间,2025 年的中国完成了两场寂静的爆破:一部动画电影与一个 AI 大模型,用各自的方式击穿了西方主流叙事的铁幕。《哪吒之魔童闹海》与 DeepSeek 的横空出世,是文化突围与科技攻坚的双重胜利,也像是一场宣言。
春节以来,关于 DeepSeek 的各种信息充斥网络,全民狂欢,有开课的,有接 API 的,还有使用 DeepSeek 写模型的。我在某播客听了技术大拿的分析后,试着借花献佛,回答一些问题。
01 DeepSeek 已经全面领先 OpenAI 了吗?
并没有,DeepSeek 目前在效率上领先没错,但局部领先并不代表整体领先。全网对 DeepSeek-R1 的吹捧有些过头了,R1 的出现固然值得欢呼,但也要保持清醒,只有正视 DeepSeek 和 OpenAI 之间的差距才能更好的进步。
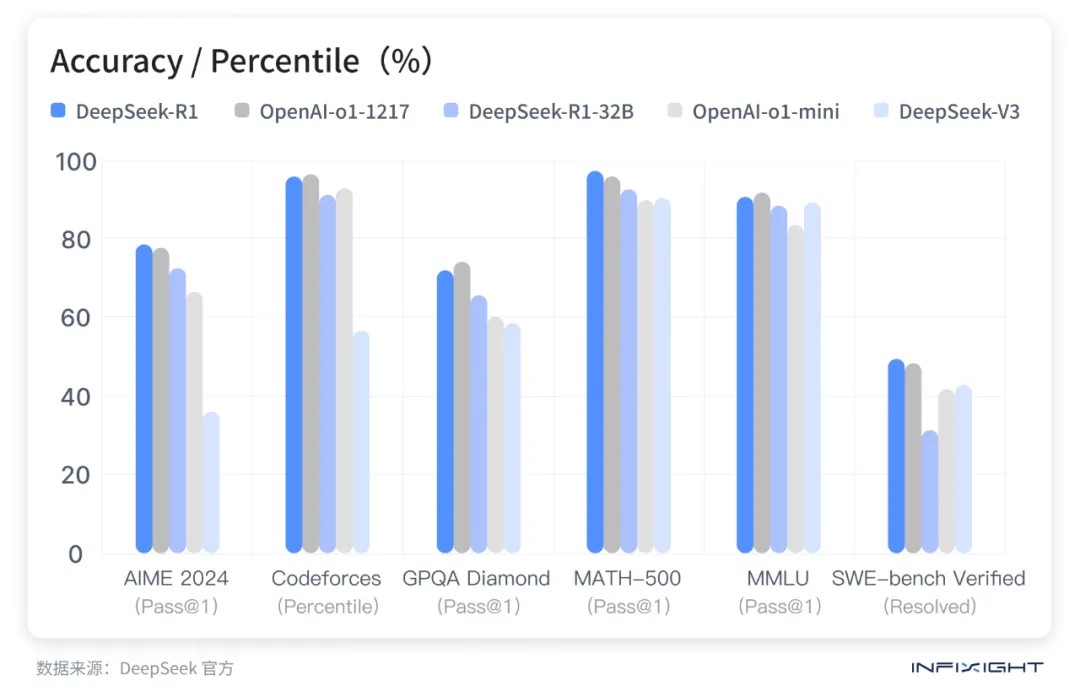
DeepSeek 官方在 1 月 20 日推出的 DeepSeek R1 版本,只是在性能上对标 OpenAI o1 正式版。而 OpenAI 已经展示了远比 o1 更强的推理模型 o3,且它的护城河依然很牢固,他们有非常充沛的算力,「星际之门」计划未来几年内拿到几百万张 B100、B200 这样量级的显卡,这是 DeepSeek 很难追赶的算力。
DeepSeek 仍然有其自身的弱点,这种弱点可能是因为蒸馏自 o1-Pro 的副作用。作为使用者,对 DeepSeek 最明显的感受就是它的 AI 幻觉相当严重。用过 DeepSeek 的人都知道它会一本正经胡说八道,让人信以为真。且经过多种测试,ChatGPT 在回答的客观性和信息的全面性上,依然优于 DeepSeek。
02 DeepSeek 和其他 AI 大模型有什么区别,为什么它会引起如此剧烈的反响?
DeepSeek-R1、R1-Zero 和 Kimi k1.5 几乎同时发布,大家的注意力几乎全在 DeepSeek 上,为什么?是因为 k1.5 不够好吗?恰恰相反,k1.5 公开的一些技术细节相当漂亮,从两个大模型公开的工作报告中可以发现,它们的相似度其实非常高,有异曲同工之妙。
开源传统的厚积薄发:造成这种国民度巨大差异的一大原因是 DeepSeek 团队在几年前就开始对外发布一些非常高质量的技术报告,同时一直保有开源传统,在各大技术社区中有比较高的知名度,这次的名声大噪属于厚积薄发。Kimi 团队则相反,一直专注于大模型本身,既没有长期发表论文,也没有开源传统,k1.5 是首次开源,在技术社区的群众优势上相对比较低。
Aha Moment(顿悟时刻):R1-Zero 通过强化学习的方式自己涌现出了复杂的推理能力,这些能力中包括反思模型。什么意思呢?就是模型在回答问题的过程中,会自己回头看刚才的答案并对答案进行重新评估,然后修正。这是模型自然涌现出来的能力,并不是 DeepSeek 研究员自己写入模型内的,这是「神之一手」,是人类开发者没有想过的,意料之外的能力,也是整个文档中的高潮。

DeepSeek 破解了 OpenAI o1 留下的谜题:如果用「惊为天人」来形容 OpenAI o1 的首次登场,那么 DeepSeek-R1 的出现则可以用「颠覆想象」来描述。OpenAI o1 通过强化学习自己学会了各种奇妙的能力,比如说检查自己的错误以及改正自己的错误。为保护其核心技术不被其他厂商轻易破解,在发布时进行了精心的隐蔽工作。如今 DeepSeek-R1 展现出了类似的性质,成为最早揭开了 OpenAI o1 谜底的大模型,且找答案的过程非常漂亮。
打破了英伟达的神话叙事:真正导致讨论升温的是 DeepSeek 是在资源极其有限的情况下,用极低的算力资源和成本诞生的。过去的主流认知是谁囤的最先进英伟达显卡多,谁在大模型的胜算就高,但显然 DeepSeek 打破了这个规则。
低得让人难以置信的成本:V3 用了不到 10% 的资金实现了 GPT4 的训练。DeepSeek 公开表示,V3 的训练共耗时 2,788 千 H800 GPU 小时,按每小时$2/GPU 计算,总成本仅 $5.576 百万美元(约 5.6M 美元,请注意这里的 5.6M 美元仅指正式训练,并不包括前期研究、架构实验等费用。)同时由于 DeepSeek 的开源,企业无需向 OpenAI 付费,就可以获得类似 o1 的推理能力。在自己的服务器,甚至本地设备上运行 R1,成本远低于 OpenAI 提供的 API。
03 网传DeepSeek拥有5万张H100显卡是真的吗?
先放结论:假的!
首先,信源无法证实。这一消息是 2024 年 11 月,一个叫 semianalysis 的半导体分析公司老板 Dylan Patel 发推特,声称 DeepSeek 拥有「超过 50,000 颗 Hopper GPU」,然而 H800 本身就是 Hopper GPU,次日又发推疑似暗示 DeepSeek 有 H100,因为可以绕过制裁。
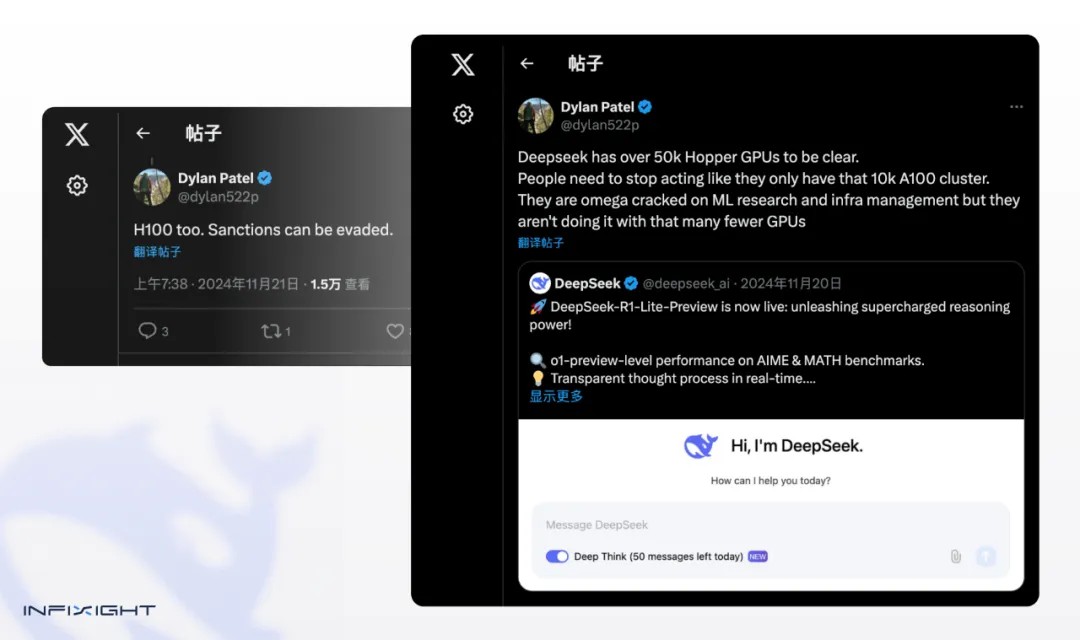
然后这个消息开始在业内传开,Scale AI 的 CEO Alexandr Wang 在接受 CNBC 采访时,不知是有意还是无意,描述的「包括了一些 H100 的五万张 Hopper GPU」在媒体传播链中就变成了「五万张 H100 GPU」。尽管 Dylan 后期有辟谣,但很多不明就里的网友就认定了「DeepSeek 拥有五万张 H100 GPU」。
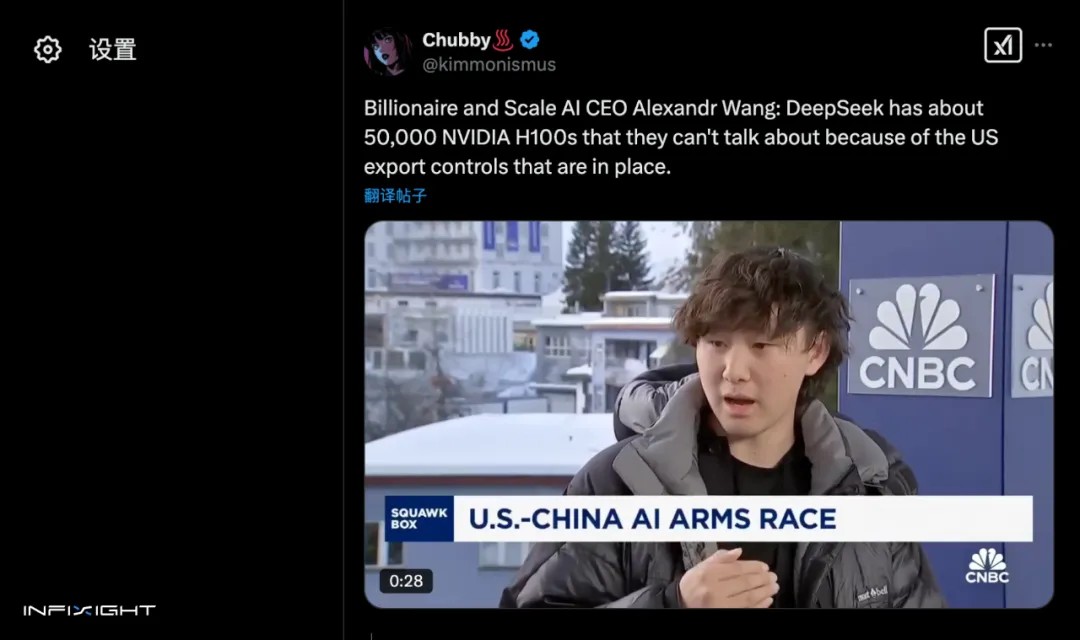
其次,DeepSeek 的 Paper 中并没有明确提到自家拥有 5 万张 H100 GPU。且 News Letter 的创始人,同时也是全球最懂技术的分析师之一的 Ben Thompson 所主持的关于 DeepSeek 的播客中提到,DeepSeek 很多技术上的创新,都是为了克服 H800 带来的宽带限制,比如工程师不得不直接使用 PTX(Parallel Thread Execution),一种类似于汇编语言的底层指令集。这种极端的优化,只有在被迫使用 H800 而无法使用 H100 时才有意义。进一步证实了 DeepSeek 并不像外界所传的那样拥有 5 万张 H100 GPU。
04 DeepSeek 适合做什么?
DeepSeek-R1 适合做逻辑推理,比如解答数学题、逻辑分析题、代码生成以及 Debug,应用在餐饮、烘焙、商超零售行业,能给用户自动生成巡检模板、员工培训试题、营销策略生成等。而 V3 是纯文本模型,适合做代码生成、文案生成、营销策略生成。
在当今数据驱动的商业环境中,DeepSeek 为企业提供了一系列创新的解决方案思路,以优化运营流程和提升顾客体验。
•自动化顾客反馈分析
通过分析顾客的在线评论、社交媒体帖子和直接反馈,DeepSeek 能够自动识别和分类关键意见和建议。具体实现上,该模型解析大量文本数据,提取有价值的信息,并生成报告,辅助管理层做出数据驱动的决策。
•智能客服系统的集成
DeepSeek 模型的集成使企业能够提供全天候的自动化客户支持,解答关于营业时间、产品信息等常见问题。此外,系统还能根据顾客的历史交互记录提供个性化服务,从而提升顾客满意度。智能助手利用 DeepSeek 理解复杂的自然语言请求,并给出准确的回答。
•内部文档管理和知识库的优化
DeepSeek 的文本处理能力在内部文档管理和知识库建设中发挥着关键作用。它能够快速检索和整理公司内部文档,提高工作效率,并根据最新的行业标准和技术动态自动更新员工培训材料。这使得员工能够迅速找到所需信息,保持知识的最新性。
•增强顾客互动和个性化营销
DeepSeek 模型还能够基于顾客的购买历史和偏好提供定制化的产品推荐,以及设计更具吸引力的营销文案,从而提升顾客参与度。通过生成针对不同顾客群体的个性化内容,DeepSeek 优化了营销活动的效果,增强了顾客互动。
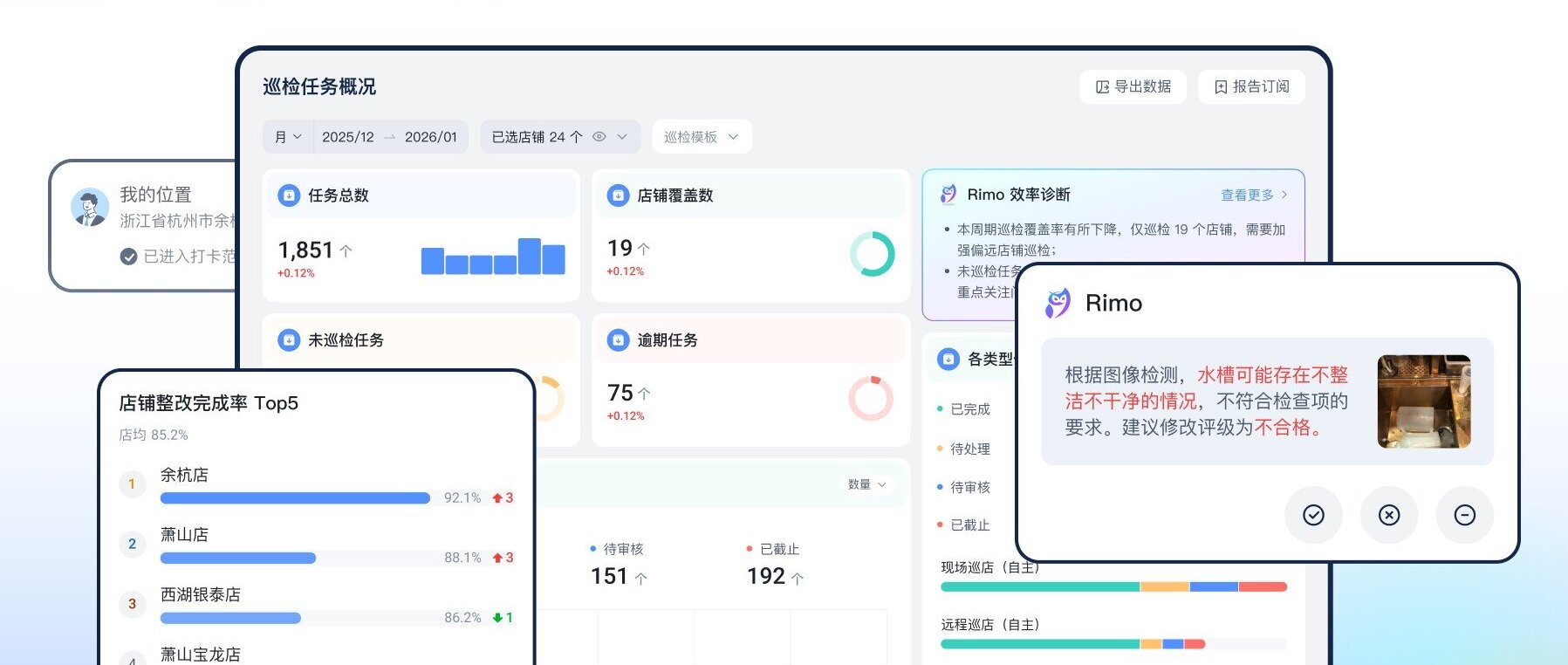
InfiSight智睿视界的目标是通过技术赋能连锁门店AI智能巡检,DeepSeek 的多模态处理能力在 InfiSight 智睿视界中展现得尤为突出。该系统可同时解析视频监控画面、货架图像扫描数据和员工操作日志文本,自动识别门店安全隐患(如消防通道堵塞)、陈列合规性问题(如商品标签错位)及服务流程偏差(如未按标准清洁)。通过跨模态数据融合,生成包含可视化热力图与整改建议的巡检报告,帮助管理者精准定位问题,推动连锁门店实现智能化、标准化、合规化运营,管理效率提升超40%。
DeepSeek 很好,有它的明显优势,期待国内出现越来越多像 DeepSeek 这样的产品,也希望大家能对当前全网对 DeepSeek 的造神氛围保持警惕。

添加小助手
推荐阅读
-
 315 知名连锁爆雷,别只骂加盟商......
315 知名连锁爆雷,别只骂加盟商......2026.03.16
-
 全新亮相!智睿视界推出连锁行业首个「AuditClaw」,AI 全面接管巡店工作流
全新亮相!智睿视界推出连锁行业首个「AuditClaw」,AI 全面接管巡店工作流2026.03.10
-
 AI 管店,真能管出「万店如一」?
AI 管店,真能管出「万店如一」?2026.03.10
